IBM Capstone Project
SpaceX - Data Collection with Web Scraping
This is the capstone project required to get the IBM Data Science Professional Certificate. Yan Luo, a data scientist and developer, and Joseph Santarcangelo, both data scientists at IBM, directed the project. The project will be presented in seven sections, and the lecture Jupyter notebooks and tutorials were used to compile the contents.
As a data scientist, I was tasked with forecasting if the first stage of the SpaceX Falcon 9 rocket will land successfully, so that a rival firm might submit better informed bids for a rocket launch against SpaceX. On its website, SpaceX promotes Falcon 9 rocket launches for 62 million dollars, whereas other companies charge upwards of 165 million dollars. A significant portion of the savings is attributable to SpaceX's ability to reuse the first stage. If we can determine whether the first stage will land, we can calculate the launch cost. This information might be useful if an alternative company want to compete with SpaceX for a rocket launch. In this project, I will conduct data science methodology including business understanding, data collection, data wrangling, exploratory data analysis, data visualization, model development, model evaluation, and stakeholder reporting.
The second part of the IBM Capsone Project involves web scraping to obtain past Falcon 9 launch data from the Wikipedia page List of Falcon 9 and Falcon Heavy launches. We will use BeautifulSoup to scrape the web for data about Falcon 9 launches and create a data frame in Pandas from the table. Let's get this step started by importing the necessary packages.
!pip3 install beautifulsoup4
!pip3 install requests
import sys
import requests
from bs4 import BeautifulSoup
import re
import unicodedata
import pandas as pd
Following this, we will use previously supplied helper functions to parse an HTML table extracted from the web.
- The date time function retrieves data from an HTML table cell, including the time and date.
- The HTML table cell's booster version is returned by the booster version function.
- The HTML table cell's landing status is returned by the landing_status function.
- The "kg" statement in the table is what the get mass function is looking for so that it can return the mass values.
- The landing status is extracted from the HTML table cell and returned by the extract column from header function
def date_time(table_cells):
return [data_time.strip() for data_time in list(table_cells.strings)][0:2]
def booster_version(table_cells):
out=''.join([booster_version for i,booster_version in enumerate( table_cells.strings) if i%2==0][0:-1])
return out
def landing_status(table_cells):
out=[i for i in table_cells.strings][0]
return out
def get_mass(table_cells):
mass=unicodedata.normalize("NFKD", table_cells.text).strip()
if mass:
mass.find("kg")
new_mass=mass[0:mass.find("kg")+2]
else:
new_mass=0
return new_mass
def extract_column_from_header(row):
if (row.br):
row.br.extract()
if row.a:
row.a.extract()
if row.sup:
row.sup.extract()
colunm_name = ' '.join(row.contents)
# Filter the digit and empty names
if not(colunm_name.strip().isdigit()):
colunm_name = colunm_name.strip()
return colunm_name
After introducing the functions, we begin by assigning the HTML page's static URL to an object in order to execute a request. get(static url).text method to retrieve an HTTP response and assign it in text format to an object. Using the BeautifulSoup() function, we then generate an object containing the response's text content.
static_url = "https://en.wikipedia.org/w/index.php?title=List_of_Falcon_9_and_Falcon_Heavy_launches&oldid=1027686922"
response=requests.get(static_url).text
soup=BeautifulSoup(response)
The following step is to collect all important column names from the HTML table header. Let's begin by locating all tables on the wiki page. To accomplish this, we utilize the find_all() function of the BeautifulSoup object with the "table" string as the function's input and assign the result to a list named "html tables."
html_tables=soup.find_all("table")
The next step is to iterate over each "th" element and execute the provided extract column from header() function to get the column names. In the following phase, we append the name of the column if it is not empty ('if name is not None and len(name) > 0') to a list we've named column names.
column_names = []
element = first_launch_table.find_all('th')
for row in range(len(element)):
try:
name = extract_column_from_header(element[row])
if (name is not None and len(name) > 0):
column_names.append(name)
except:
pass
print(column_names)

In the first part of this project, we will make an empty dictionary with keys made from the extracted column names. Later, this dictionary will be converted into a Pandas dataframe. While doing so, we also adjust the columns of the table to make them identical with the dataset from the previous section. We remove 'Date and time ()' column because we will define the "Date' and 'Time' columns separately. In addition to them, we will also add 'Version Booster' and 'Booster landing' columns by using the following syntax.
launch_dict= dict.fromkeys(column_names)
del launch_dict['Date and time ( )']
launch_dict['Flight No.'] = []
launch_dict['Launch site'] = []
launch_dict['Payload'] = []
launch_dict['Payload mass'] = []
launch_dict['Orbit'] = []
launch_dict['Customer'] = []
launch_dict['Launch outcome'] = []
launch_dict['Version Booster']=[]
launch_dict['Booster landing']=[]
launch_dict['Date']=[]
launch_dict['Time']=[]
The next step is to import launch records from the table rows into the launch dict. Unexpected annotations and other noises, such as reference links B0004.1[8], missing values N/A [e], inconsistent formatting, etc., are common in HTML tables on Wiki sites.
In order to facilitate the parsing process, the instructors have provided us with an incomplete code sample to help us complete the launch dict. Thecomplete syntax presented below extracts each table, then iterates through each row to determine whether the first table heading corresponds to a launch number. Then, each cell of the table is examined to see whether it contains a number or a string. If the value is a number, it is stored in the associated dictionary.
extracted_row = 0
for table_number,table in enumerate(soup.find_all('table',"wikitable plainrowheaders collapsible")):
for rows in table.find_all("tr"):
if rows.th:
if rows.th.string:
flight_number=rows.th.string.strip()
flag=flight_number.isdigit()
else:
flag=False
row=rows.find_all('td')
if flag:
extracted_row += 1
launch_dict['Flight No.'].append(flight_number)
datatimelist=date_time(row[0])
date = datatimelist[0].strip(',')
launch_dict['Date'].append(date)
time = datatimelist[1]
launch_dict['Time'].append(time)
bv=booster_version(row[1])
if not(bv):
bv=row[1].a.string
print(bv)
launch_dict['Version Booster'].append(bv)
launch_site = row[2].a.string
launch_dict['Launch site'].append(launch_site)
payload = row[3].a.string
launch_dict['Payload'].append(payload)
payload_mass = get_mass(row[4])
launch_dict['Payload mass'].append(payload_mass)
orbit = row[5].a.string
launch_dict['Orbit'].append(orbit)
if row[6].a != None:
customer = row[6].a.string
else:
customer = ''
launch_dict['Customer'].append(customer)
launch_outcome = list(row[7].strings)[0]
launch_dict['Launch outcome'].append(launch_outcome)
booster_landing = landing_status(row[8])
launch_dict['Booster landing'].append(booster_landing)
After the values from the parsed launch records have been entered into launch dict, a dataframe can be constructed using them.
launch_dict
df=pd.DataFrame(launch_dict)
df
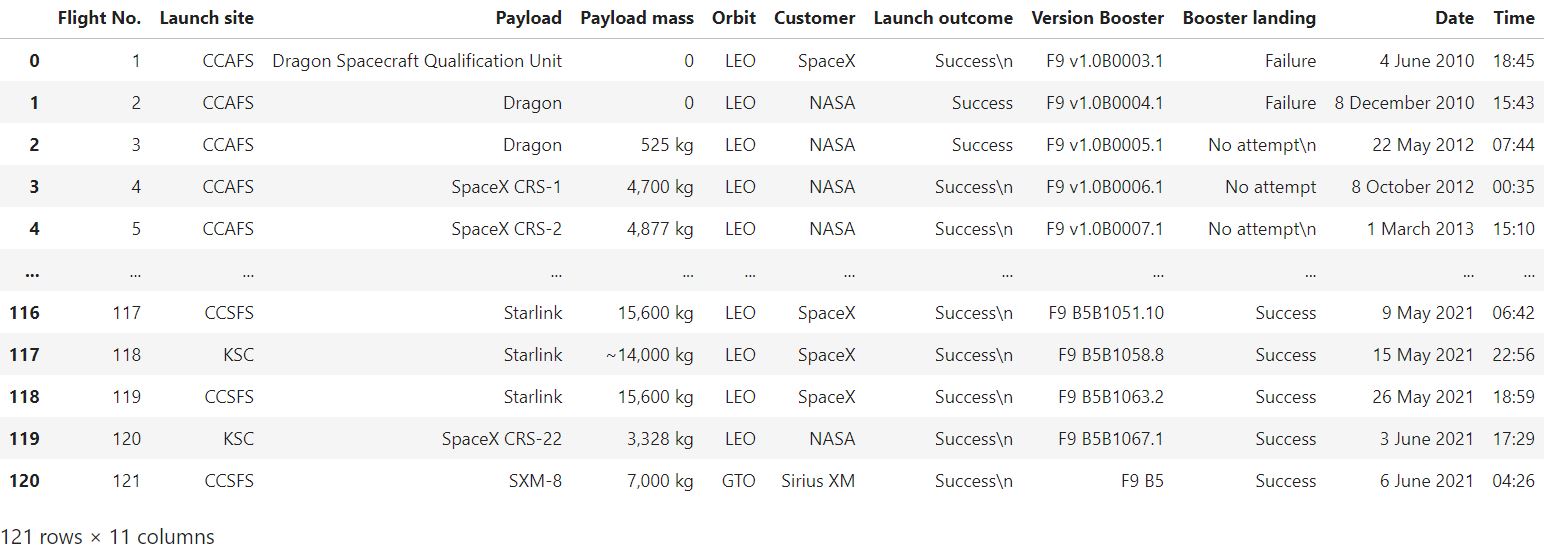
Now that we have gotten this far, we can save it as a CSV file for later use..
df.to_csv('spacex_web_scraped_tpf.csv', index=False)